

AWS Lambda関数でSeleniumを動かすのに非常に苦労しました。どうにか動作することができたので、備忘録をまとめておきます。
目次
はじめに 苦労したことと対応方針
- headless-chromiumとchromedriverのバージョン組み合わせ問題
→headless-chromiumをv1.0.0-37、chromedriverを2.37にする。
AWS Lambda関数でheadless-chromiumとchromedriverを動かそうとしたのですが、特定のバージョンの組み合わせでなければ動作しませんでした。
バージョンの組み合わせを調査した結果、以下の組み合わせで動作することが分かりました。
| headless-chromium のバージョン | chromedriver のバージョン |
|---|---|
| v1.0.0-38 ・cchromium 64.0.3282.186 | 2.37 ・ChromeDriver v2.37 ・Supports Chrome v64-66 |
| v1.0.0-37 ・chromium 64.0.3282.167 | 2.37 ・ChromeDriver v2.37 ・Supports Chrome v64-66 |
詳細は以下のブログでまとめたので、よろしければご覧ください。

- Seleniumのバージョンにより使いたいメソッドが動作しない。
→Selenium 3.141.0をインストールする
アクセスしたサイト内で特定のIDからelementを検索するために、webdriver.Chrome().browser.find_element().submit()やwebdriver.Chrome().browser.find_element().click()を使うのですが、「'dict' object has no attribute 'submit'」や「'dict' object has no attribute 'click'」というエラーがでてしまった。
このエラーを検索すると、以下のサイトを見つけて、Selenium 4.0のバグ?が原因みたいなので、Selenium 3.141.0をインストールすることにしました。
AWS Lambdaレイヤの構築
PythonでSeleniumを実行するためには、Seleniumライブラリやheadless-chromium、chromedriverといったソフトウェアが必要となり、pipやaptでPythonの実行環境にインストールする必要があります。
一方、AWS Lambdaのデフォルト設定ではPythonの実行環境のみの提供であり、pipやaptなどでインストールした外部ライブラリについては事前にその実行環境にインストールされるように設定しないといけません。
その設定方法として、AWS Lambdaでは「Lambdaレイヤ」と呼ばれるものがあります。
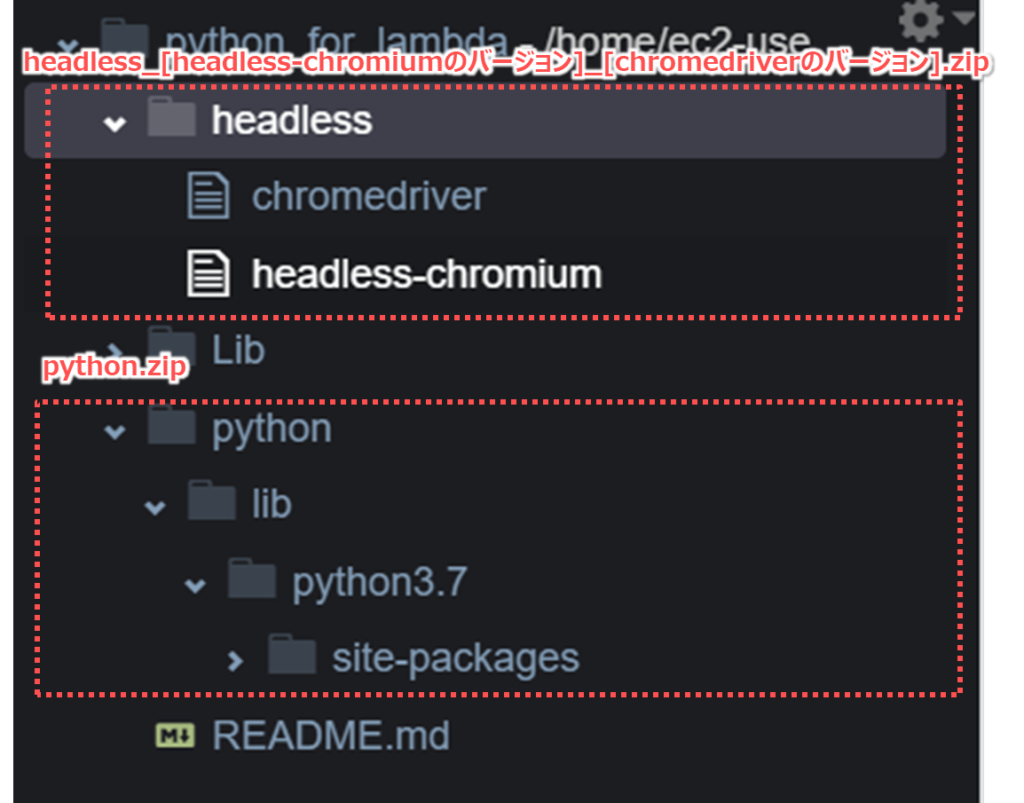
ここではまず、Selenium、chromedriver、headless-chromiumはAWS Cloud9で構築し、それをZIPファイル化します。
| 用途 | ZIPファイルの名前 | Lambdaレイヤの名前 |
|---|---|---|
| PythonのSeleniumライブラリ | python.zip | selenium (レイヤにZIPファイルを紐づけ) |
| headless-chromiumと chromedriver | headless _[headless-chromiumのバージョン] _[chromedriverのバージョン].zip | headless (ZIPファイルはS3に格納し、 レイヤにはS3のURLを紐づけ) |
以下に簡単な構築手順をまとめました。
AWS LambdaレイヤにアタッチするZIPファイルを作成する
AWS LambdaレイヤにアタッチするZIPファイルを2つ作成します。
- python.zip
- Seleniumを格納したZIPファイル
- [python/lib/python3.7/site-packages/*]にSeleniumをインストールします。
- headless_[headless-chromiumのバージョン]_[chromedriverのバージョン].zip
- headless-chromiumとchromedriverを格納したZIPファイル
- [headless/*]に各ファイルをダウンロードします。
以下に、AWS Lambdaレイヤ用の環境を準備する方法をまとめました。
- AWSマネージメントコンソールにログインする。
- 「AWS Cloud9」にアクセスして、[Create environment]をクリックする。
- [Name environment]画面が開いたら、Name、Descriptionを入力して[Next step]をクリックする。
| 設定項目 | 設定例 |
|---|---|
| Name | 任意のCloud9の環境名 (例: python_for_lambda) |
| Description | Cloud9の環境の説明 (オプションのため空欄でも可) |
- [Configure settings]画面が開いたら、EC2の最小構成を選択して[Next step]をクリックする。
| 設定項目 | 設定例 |
|---|---|
| Environment type | Create a new EC2 instance for environment(direct access) |
| Instance type | t2.micro (1 GiB RAM + 1 vCPU) |
| Platform | Amazon Linux 2 (recommended) |
| Cost-saving setting | After 30 minutes (default) |
| LAM role | AWSServiceRoleForAWSCloud9(固定) |
- [Review]画面が開いたら、内容を確認して問題なければ、[Create environment]をクリックする。
- EC2の生成が完了したら、以下のようにEC2の編集画面が出てくる。
- 下部にあるコマンドコンソール部分で以下のコマンドを実行し、Seleniumをインストールする。
$ pip install selenium==3.141.0 -t python/lib/python3.7/site-packages
- 同じく下部にあるコマンドコンソール部分で以下のコマンドを実行し、headless-chromiumとchromedriverをダウンロードする。
【headless-chromiumのダウンロード】
$ mkdir -p headless
$ curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
$ unzip -o headless/headless-chromium.zip -d ./headless
$ rm headless/headless-chromium.zip
【chromedriverのダウンロード】
$ curl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zip
$ unzip -o chromedriver.zip -d ./headless
$ rm headless/chromedriver.zip
- pythonフォルダをpython.zipという名前でダウンロードする。
- headlessフォルダをheadless_[headless-chromiumのバージョン]_[chromedriverのバージョン].zipという名前でダウンロードする。
Selenium、headless-chromiumとchromedriverをダウンロード完了すると、Cloud9のフォルダ構成は以下のようになっていると思います。
各フォルダを[右クリック > ダウンロード]を選択することでZIPファイルとしてダウンロードできます。
Selenium用のLambdaレイヤを作成する
前手順で作成したSeleniumライブラリが格納された「python.zip」を起動させるLambdaレイヤを作成します。
以下に、AWS Lambdaレイヤ用の環境を準備する方法をまとめました。
- AWSマネージメントコンソールにログインする。
- 「AWS Lambda」にアクセスする。
- 左側のメニューから「その他のリソース > レイヤー」を選択し、「レイヤーの作成」をクリックする。
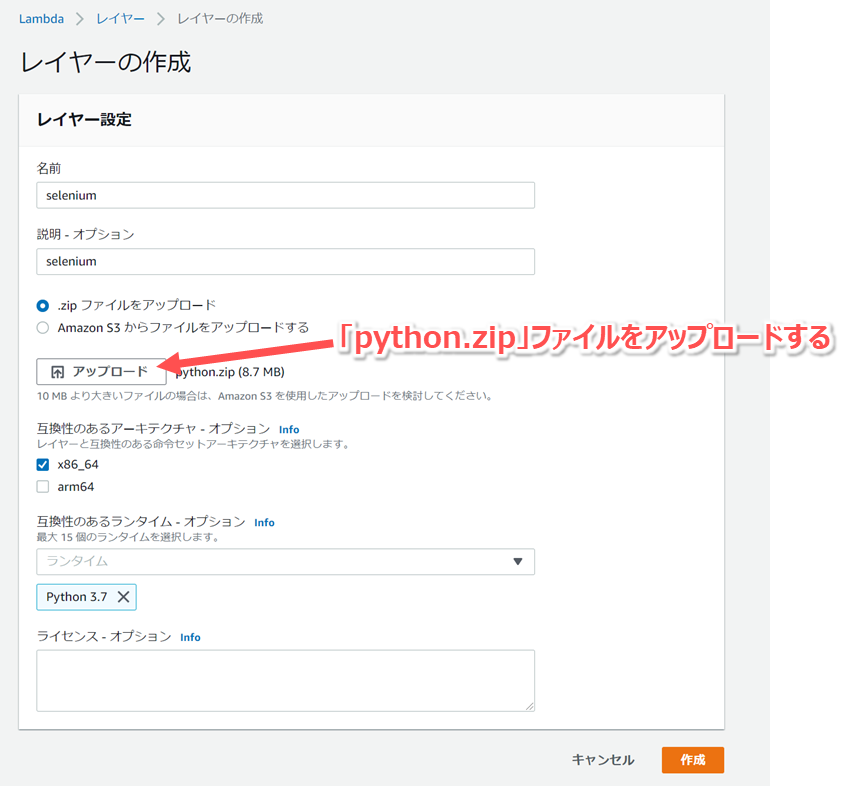
- 「レイヤー設定」画面が表示されるので、以下の設定例を参考に入力し、下部の「作成」ボタンをクリックする。
| 設定項目 | 設定例 |
|---|---|
| 名前 | selenium |
| 説明 | 任意のものを記入 |
| アップロード方法 | 「.zipファイルをアップロード」にチェック |
| アップロード対象 | 「python.zip」をアップロード |
| 互換性のあるアーキテクチャ | 「x86_64」にチェック |
| 互換性のあるランタイム | 「Python 3.7」を選択 |
「レイヤー seleniumのバージョン*が正常に作成されました。」と表示されれば、作成完了です。
chrome関連ファイル用のLambdaレイヤを作成する
headless-chromiumとchromedriverをまとめたZIPファイルはサイズが大きいため、AWS Lambdaレイヤの「.zipファイルをアップロード」で設定するとエラーとなってしまいます。

そのため、headless-chromiumとchromedriverをまとめたZIPファイルはS3に格納したうえで、「Amazon S3からファイルをアップロードする」でLambdaレイヤの設定を行います。
chrome関連のZIPファイルをS3に格納する
- AWSマネージメントコンソールにログインする。
- 「AWS S3」にアクセスする。
- メニューから「バケット」を選択して、「バケットを作成」ボタンをクリックする。
- 「一般的な設定」画面が開くので、以下の設定値を入力し、下部にある「バケットを作成」ボタンをクリックする。
| 設定項目 | 設定例 |
|---|---|
| バケット名 | headless-chromium-yyyymmddhhmm ※「yyyymmddhhmm」に日付を入れて一意な名称にしてます |
| AWSリージョン | アジアパシフィック(東京) ap-northeast-1 |
※自分は、上記設定以外はデフォルトのままに設定しましたが、ご自分の環境に合わせて設定してください。
パケット「headless-chromium-yyyymmddhhmm」が正常に作成されました。」と表示され、バケット一覧に作成したバケット名が表示されれば、バケット作成は完了です。
次に、そのバケットにchrome関連のZIPファイルを格納します。
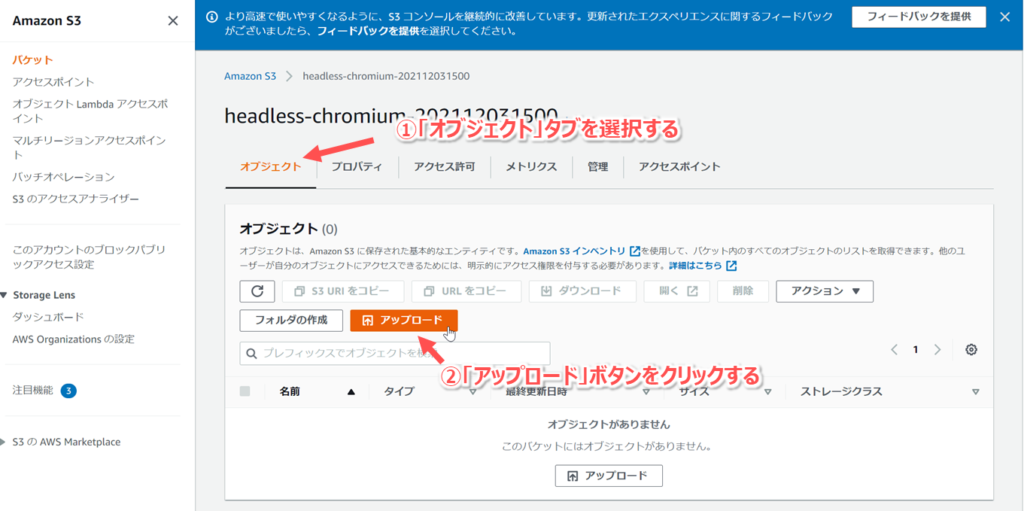
- バケット一覧の中から、上で作成したバケット名をクリックする。
- オブジェクトタブを選択し、「アップロード」ボタンをクリックする。
- 「アップロード」画面が開いたら、ファイルとフォルダの「ファイルを追加」をクリックして、前章で作成した「headless.zip」をアップロードする。
- 「アップロード」画面右下の「アップロード」ボタンをクリックする。
「アップロードが成功しました。」と表示されれば、S3の設定完了です。
- S3にアップロードした「headless.zip」のオブジェクトURLをメモする。
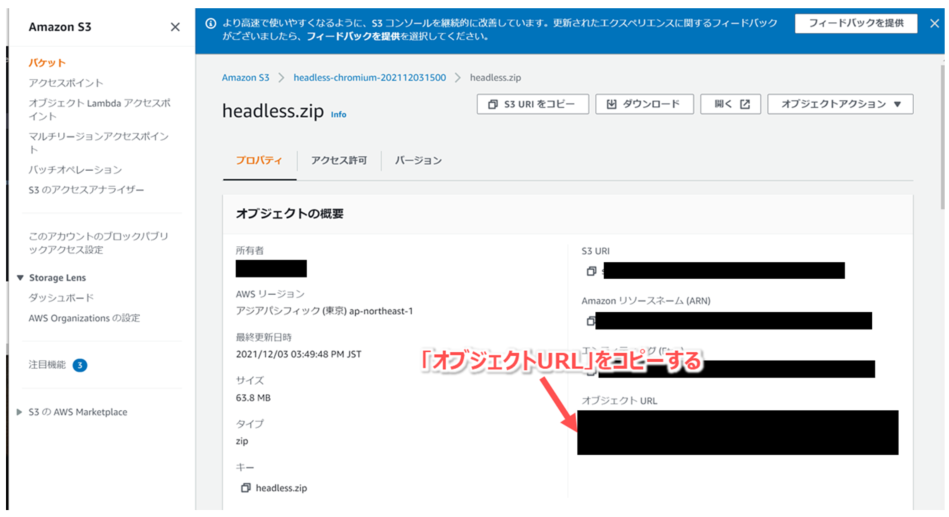
chrome関連ファイル用のLambdaレイヤを作成する
前章で作成したChrome関連ファイルが格納された「headless.zip」を起動させるLambdaレイヤを作成します。
以下に、AWS Lambdaレイヤ用の環境を準備する方法をまとめました。
- AWSマネージメントコンソールにログインする。
- 「AWS Lambda」にアクセスする。
- 左側のメニューから「その他のリソース > レイヤー」を選択し、「レイヤーの作成」をクリックする。
- 「レイヤー設定」画面が表示されるので、以下の設定例を参考に入力し、下部の「作成」ボタンをクリックする。
| 設定項目 | 設定例 |
|---|---|
| 名前 | headless |
| 説明 | 任意のものを記入 |
| アップロード方法 | 「Amazon S3からファイルをアップロードする」にチェック |
| Amazon S3のリンクURL | S3にアップロードした「headless.zip」のオブジェクトURL |
| 互換性のあるアーキテクチャ | 「x86_64」にチェック |
| 互換性のあるランタイム | 「Python 3.7」を選択 |
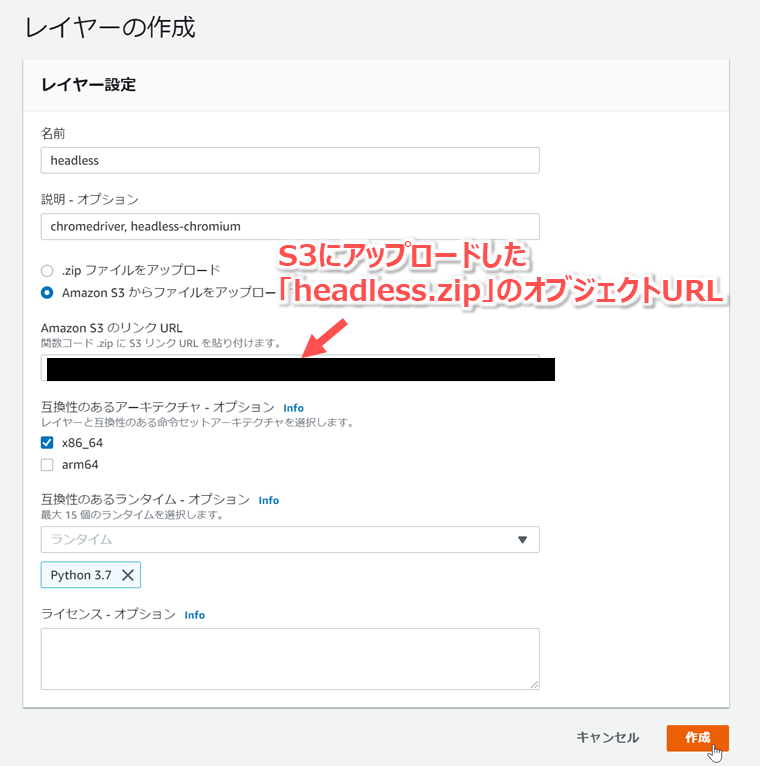
「レイヤー headlessのバージョン*が正常に作成されました。」と表示されれば、作成完了です。
AWS Lamda関数を作成する
前章でAWS Lambdaレイヤの設定ができたので、次にAWS Lambda関数の設定をし、Lambdaレイヤの紐づけを行います。
以下に、調査環境用のAWS Lambda関数を作成する方法をまとめました。
- AWSマネージメントコンソールにログインする。
- 「AWS Lambda」にアクセスする。
- ダッシュボード画面の右上にある「関数を作成」ボタンをクリックする。
- 「関数の作成」画面が表示されるので、以下の設定例を参考に入力し、下部の「関数の作成」ボタンをクリックする。
| 設定項目 | 設定例 |
|---|---|
| 関数の作成 オプション | 「一から作成」を選択 |
| 関数名 | 任意のものを記入 (例:testLambdaFunc) |
| ランタイム | Python 3.7 |
| アーキテクチャ | 「x86_64」にチェック |
| デフォルトの実行ロールの変更 | 「AWSポリシーテンプレートから新しいロールを作成」にチェック |
| ロール名 | 任意のものを記入 (例LambdaTestPolicy) |
| ポリシーテンプレート オプション | 「Amazon S3 オブジェクトの読み取り専用アクセス権限」を選択 |
※「headless.zip」をS3にアップロードしたため、ポリシーにAmazon S3の読み取り専用アクセス権限を付与してます。
「関数xxxxxを正常に作成しました。」と表示されれば、Lambda関数の作成はできています。
次に、Lambda関数で実行するコードの記入と、Lambdaレイヤを設定します。
- 先ほど作成した関数のページを開き、コードタブを選択する。
- 以下のサンプルコードを入力し、「Deploy」をクリックする。
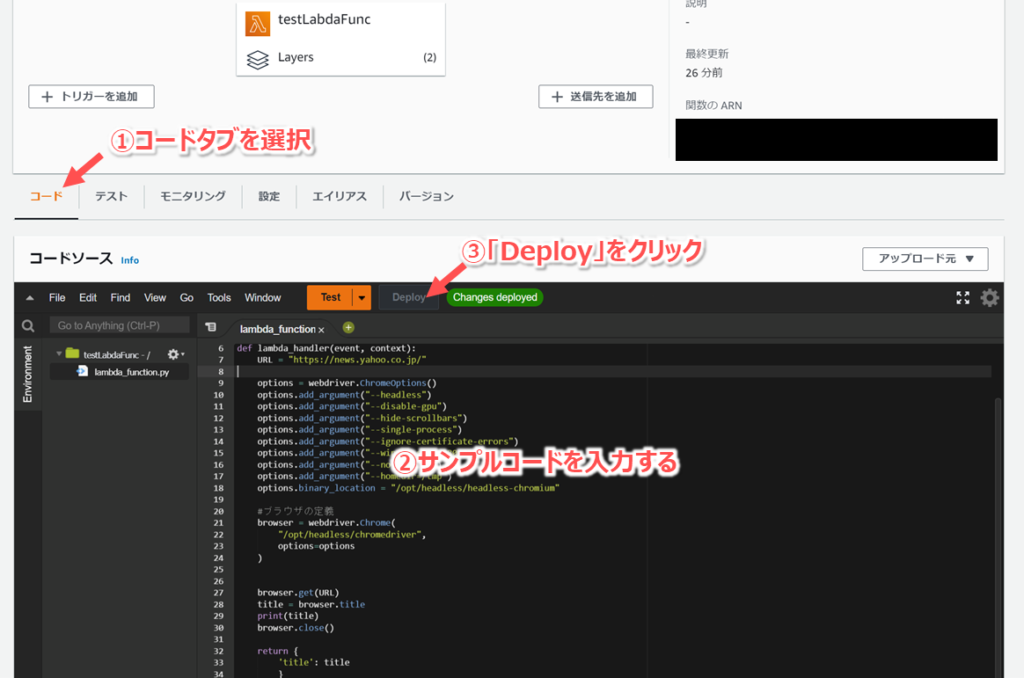
サンプルコード
import json
# python配下自動でimport
from selenium import webdriver
def lambda_handler(event, context):
URL = "https://news.yahoo.co.jp/"
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--window-size=880x996")
options.add_argument("--no-sandbox")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/headless/headless-chromium"
#ブラウザの定義
browser = webdriver.Chrome(
"/opt/headless/chromedriver",
options=options
)
browser.get(URL)
title = browser.title
browser.close()
return title- Lambdaレイヤは「/opt」ディレクトリ配下に格納されるため
/opt/headless/headless-chromiumや/opt/headless/chromedriverでheadless.zip内のファイルを指定しています。
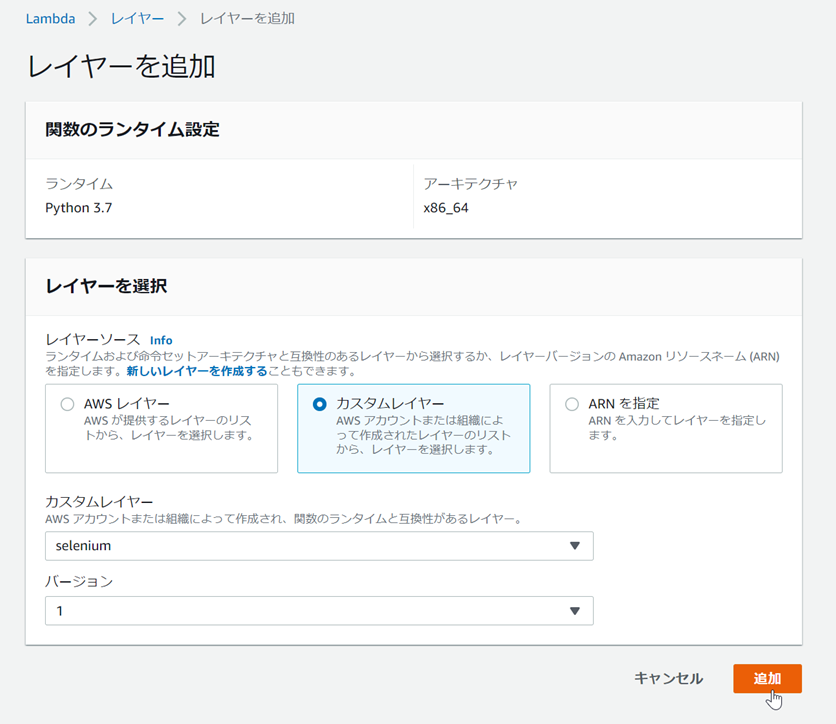
- 下部にあるレイヤーで「レイヤーの追加」をクリックする。
- 「レイヤを追加」画面が開いたら、以下のようにSelenium用のLambdaレイヤを設定して、右下の「追加」ボタンをクリックする。
| 設定項目 | 設定例 |
|---|---|
| レイヤーソース | 「カスタムレイヤー」を選択 |
| カスタムレイヤ | Selenium用のLambdaレイヤで設定したレイヤ名(例:selenium) |
| バージョン | 1 (最大5つまで登録できる、レイヤに紐づけているZIPファイルがかわると バージョンが自動で上がっていく) |
- Lambda関数の設定画面に戻ったら、同様に下部にあるレイヤーで「レイヤーの追加」をクリックする。
- 「レイヤを追加」画面が開いたら、以下のようにchrome関連ファイル用のLambdaレイヤを設定して、右下の「追加」ボタンをクリックする。
| 設定項目 | 設定例 |
|---|---|
| レイヤーソース | 「カスタムレイヤー」を選択 |
| カスタムレイヤ | chrome関連ファイル用のLambdaレイヤで設定したレイヤ名(例:headless) |
| バージョン | 1 (最大5つまで登録できる、レイヤに紐づけているZIPファイルがかわると バージョンが自動で上がっていく) |
- Lambda関数の設定画面で、「設定」タブを開き、「編集」ボタンをリリックする。
- 「基本設定を編集」画面が開いたら、以下のように設定を変更して右下の「保存」をクリックする。
| 設定項目 | 設定例 |
|---|---|
| メモリ | 256MB |
| タイムアウト | 3分3秒 |
| それ以外 | デフォルトの設定のまま |
※デフォルトの設定だとタイムアウトやメモリ不足となるため、少し多めに変更しています。
以上でAWS Lambda関数の構築は完了です。
サンプルプログラムでSeleniumの動作確認
上で構築した調査環境でテストを実施します。
- Lambda関数の設定画面で、「テスト」タブを開き、特に変更せず「テスト」ボタンをクリックする。
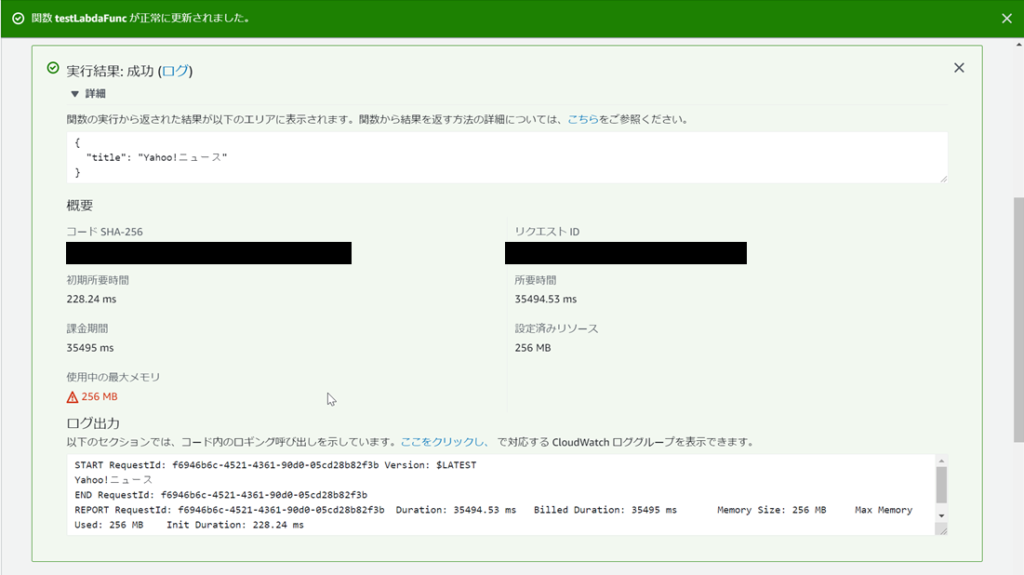
実行結果が成功となれば動作しています!
以上!


コメント