

csvファイルを扱うことができるPythonライブラリであるpandasを使って、csvファイルから重複な行を削除する方法を備忘録として残しておきます。
目次
サンプルのcsvファイル
使い方をまとめる上で、以下の「duplicated_sample .csv」という名称のcsvファイルをCドライブ直下に格納したことを想定します。
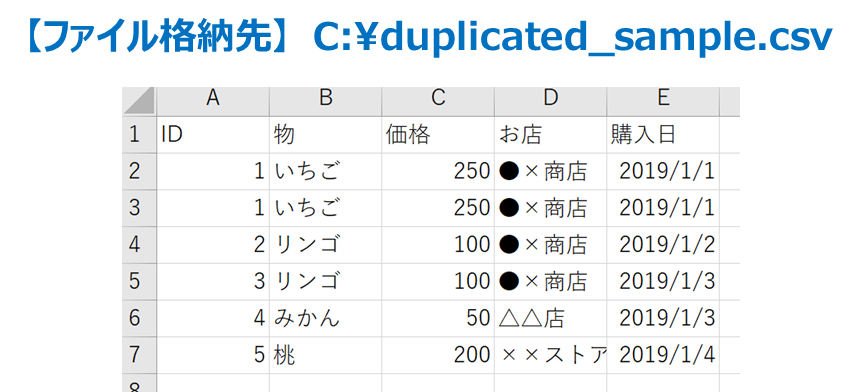
以下のサンプルコードでは、D列のお店のデータをSeriesオブジェクトとして取り出し、重複するものを削除してユニークなSeriesオブジェクト/NumpyArrayオブジェクトとして取得します。
csvファイルから重複な行を削除する
【サンプルコード】
##### 【csvファイルから重複な行を削除する】 #####
import pandas
# 重複ありcsvファイルのロード
csvfile_path='C:/duplicated_sample.csv'
dataframe = pandas.read_csv(filepath_or_buffer=csvfile_path,encoding="cp932")
# 「お店」のSeriesを取得
series = dataframe['お店']
# 重複チェック
print('===== 重複チェック =====')
print(f'重複チェック: {series.duplicated().any()}')
# ユニークなSeriesを取り出し
print('===== drop_duplicates() ユニークなSeriesを取り出し =====')
print(f'データタイプ: {type(series.drop_duplicates())}')
print(series.drop_duplicates())
# ユニークなSeriesをNumpyArrayで取り出し
print('===== unique() ユニークなNumpyArrayを取り出し =====')
print(f'データタイプ: {type(series.unique())}')
print(series.unique())
【実行結果】
===== 重複チェック =====
重複チェック: True
===== drop_duplicates() ユニークなSeriesを取り出し =====
データタイプ: <class 'pandas.core.series.Series'>
0 ●×商店
4 △△店
5 ××ストア
Name: お店, dtype: object
===== unique() ユニークなNumpyArrayを取り出し =====
データタイプ: <class 'numpy.ndarray'>
['●×商店' '△△店' '××ストア']
【説明】
dataframe = pandas.read_csv(filepath_or_buffer=csvfile_path,encoding="cp932")で「duplicated_sample .csv」から有効なデータのみをDataFrameオブジェクトとして取得しています。series = dataframe['お店']で、そのDataFrameオブジェクトから、'お店'列(「duplicated_sample .csv」のD列)をpandasのSeriesオブジェクトとして取得しています。- 重複チェックについて
- pandasの
Seriesオブジェクトのduplicated()を使うことで、重複した行を抽出し、さらに.any()を実行することで重複有無をチェックしています。 - 【実行結果】は、「duplicated_sample .csv」の2行目~5行目まで「●×商店」が重複しているので、Trueになります。
- pandasの
Seriesオブジェクトのduplicated()の詳細については本家のAPI仕様書である<pandas.Series.duplicated>を参照してください。
- pandasの
- ユニークなSeriesを取り出しについて
- pandasの
Seriesオブジェクトのdrop_duplicates()を使うことで、重複した内容を削除することができます。 - 【実行結果】は、「duplicated_sample .csv」のお店列の重複が削除され、「●×商店」、「△△店」、「××ストア」のみの
Seriesオブジェクトが取得できています。 - pandasの
Seriesオブジェクトのdrop_duplicates()の詳細については本家のAPI仕様書である<pandas.Series.drop_duplicates>を参照してください。
- pandasの
- ユニークなNumpyArrayを取り出しについて
- pandasの
Seriesオブジェクトのunique()を使うことで、drop_duplicates()同様に重複した内容を削除することができます。ただし、unique()はnumpy.ndarrayオブジェクトを返します。 - 【実行結果】は、「duplicated_sample .csv」のお店列の重複が削除され、「●×商店」、「△△店」、「××ストア」のみの
numpy.ndarrayオブジェクトが取得できています。 - pandasの
Seriesオブジェクトのunique()の詳細については本家のAPI仕様書である<pandas.Series.unique>を参照してください。
- pandasの
関連情報
【pandasライブラリのまとめ】

【Pythonライブラリのまとめ】

以上!


コメント